요즘은 ORM으로 작업을 많이 하니까 SQL.. 자세히 몰라도 되는거 아닐까? SQL을 알아야 하는 이유는 무엇일까?
❗️ ORM은 SQL을 쉽게 사용하기 위하여, 접근성을 위해 만들어진 하나의 도구
ORM이 왜 나오게 되었는지
SQL 동작원리는 어떻게 된건지
ORM이 없을 때는 어떻게 해야하는지
제일 중요한 것은 가장 기본적인 것, DB에 직접 접근해서 데이터를 열람하거나 필터링 할 수 있어야 합니다.
SELECT 문
MySQL CLI를 실행하여 로그인을 한 후
MySQL 서버에 있는 데이터베이스 목록 표시
mysql> show databases;
데이터베이스 사용
mysql> use DB명;
해당 데이터베이스의 테이블 목록 표시
mysql> show tables;
연산자 우선순위(MySQL)
연산자
우선순위
INTERVAL
높음
BINARY, COLLATE
-(단항 감산), ~(단항 비트 반전)
^
*, /, DIV, %, MOD
-, +
&
|
=, <=>, >=, >, <=, <, <>, !=, IS, LIKE, REGEXP, IN
BETWEEN, CASE, WHEN, THEN, ELSE
NOT
&&, AND
XOR
||, OR
=(대입 등호), :=
낮음
SQL의 기초적인 기술 규칙
SQL 문의 마지막에 딜리미터를 붙인다 (대부분 세미콜론)
키워드는 case-sensitive 하지 않다 (select와 SELECT는 같다)
정수는 그대로 쓴다. 문자열, 날짜 및 시각은 작은 따옴표로 감싼다
단어는 반각 스페이스나 개행으로 구별한다
DISTINCT
선택한 행에서 중복된 값이 있고 이를 없애려고 하는 경우
SELECT DISTINCT 컬럼명 FROM 테이블명 WHERE 조건;
ORDER BY
SELECT ~ FROM 테이블명 ORDER BY 정렬키1[, 정렬키2, ... DESC/ASC];
행의 순서를 확실히 같게 하려면 행의 정렬키를 unique하게 정해야 함
정렬키가 같은 값의 행이 복수 개 존재한다면 그 행들의 순서는 일정하지 않기 때문
기본값 : ASC(오름차순)
집약함수
기본적으로 NULL을 제외하고 집계
COUNT 함수만은 'COUNT(*)'로 표기(NULL을 포함한 전체 행 집계)
COUNT 테이블 행수
SUM 테이블 수치 데이터 합계
AVG 테이블 수치 데이터 평균
MAX 테이블 임의열 데이터 중 최대값
MIN 테이블 임의열 데이터 최소값
(MySQL only) GROUP_CONCAT 문자열 결합, 콤마로 구분
# GROUP_CONCAT과 DISTINCT로 중복 회피
# 중복이 없어지고 행정구역이 1회만 조회
mysql> SELECT GROUP_CONCAT(DISTINCT district) FROM CITY WHERE COUNTRYCODE='KOR';
GROUP BY
데이터를 몇 개의 그룹으로 나눠서 집약하는 것
SELECT ~ FROM 테이블명 GROUP BY 컬럼명1 [, 컬럼명2, ...];
GROUP BY로 지정한 열 : 집약 키, 그룹화 키
복수 열을 콤마로 구분해 지정
HAVING
그룹마다 집약한 값을 조건으로 선택하는 것
SELECT ~ FROM GROUP BY ~ HAVING 그룹의 값에 대한 조건;
작성 순서
SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BY
실행 순서
FROM
ON, WHERE
JOIN, GROUP BY
HAVING
SELECT
ORDER BY
LIMIT (MySQL) / ROWNUM (Oracle)
UPDATE, INSERT, DELETE 문
UPDATE
UPDATE 테이블명 SET 컬럼명1=값1[,컬럼명2=값2,...] WHERE 조건;
갱신하는 열에 디폴트 값이 있는 경우 : 값 대신 'DEFAULT' 키워드를 지정하면 기본값으로 갱신됨
INSERT
INSERT는 행 단위로 수행되므로 테이블 정의를 정확히 확인 후 실행되어야 함
\G는 ; 대신에 사용할 수 있는 딜리미터로 결과를 세로로 보기 쉽게 함
SHOW CREATE TABLE 테이블명\G
# 테이블 정의 자체가 아닌 단순히 열 정보 조회용 (Oracle 호환)
DESC 테이블명;
INSERT문
# 기본
INSERT INTO 테이블명(컬럼1[,컬럼2,...]) VALUES (값1[,값2,...]);
# Multi row insert (MySQL)
INSERT INTO city (name, code, district) VALUES ('Gimpo', 'KOR', 'Kyonggi'),
('Seongnam', 'KOR', 'Kyonggi'), ('Hwaseong', 'KOR', 'Kyonggi');
# 자주 사용되는 구문
INSERT INTO 테이블1 SELECT FROM 테이블2; # SELECT문의 결과 값을 레코드로 입력
DELETE
DELETE FROM 테이블명 WHERE 조건;
VIEW
가상의 테이블, 접근이 허용된 데이터만 보여줄 수 있음(테이블과 동일하지만 테이블과 같은 데이터는 가지고 있지 않음)
VIEW 언제 쓸까? VIEW의 이점
설계를 변경할 수 없을 때 뷰로 데이터를 간소화하자!
편리성 : 복잡한 SELECT 문을 일일이 매번 기술할 필요가 없다. 데이터 저장 없이(기억장치의 용량을 사용하지 않고) 실현할 수 있다.
보안성 : 필요한 열과 행만 사용자에게 보여줄 수 있다. 민감한 컬럼은 마스킹하기
독립성 : 기존 테이블 구조가 변경되면 뷰도 함께 변경, 갱신 시에도 뷰 정의에 따른 갱신으로 한정할 수 있다. 뷰를 제거(DROP VIEW)해도 참조하는 테이블은 영향을 받지 않는다.
VIEW 작성
CREATE VIEW 뷰이름(열명1[, 열명2, ...]) AS SELECT문;
VIEW 입력, 갱신 제한
갱신 불가
어떤 행이 대응하는지 모르거나 어떤 값을 넣으면 좋을지 모르는 경우
삽입 불가
2가지 이상 테이블을 조합해 작성한 뷰를 갱신할 때 어느 테이블을 갱신하면 좋을지 알 수 없는 경우
선택된 열 이외의 열에 기본값도 없고 NULL도 허용되지 않는 상황 (해당 열에 넣을 수 있는 값이 없는 경우)
SUBQUERY
하나의 SQL 문에 포함되어 있는 또 다른 SQL 문
주의사항
괄호로 감싸서 사용할 것
ORDER BY를 사용하지 못한다
단일 행 또는 복수 행 비교 연산자와 함께 사용할 수 있다
SELECT -- 스칼라 서브쿼리
FROM -- 인라인 뷰
WHERE -- 중첩 서브쿼리 등
HAVING -- 중첩 서브쿼리 등
ORDER BY -- 스칼라 서브쿼리
-- 테이블2의 정보를 뽑아서 그 데이터를 테이블1에 넣어준다.
-- value()들어갈 자리를 서브쿼리로 대체 했다.
INSERT INTO table1 (SELECT * FROM table2);
-- 인턴의 정보를 구해와서 삭제한다.
DELETE FROM employee
WHERE id = (SELECT id FROM employee where office_worker = '인턴' );
-- 인턴에 정보를 구해와서 급여를 10만원 인상한다.
UPDATE employee SET salary=(salary+100000)
WHERE id = (SELECT id FROM employee where office_worker = '인턴' );
스칼라 서브쿼리 : 한 행만 반환
인라인 뷰 : SQL문이 실행될 때만 생성되는 뷰이기 때문에 DB에 저장되지 않음 (동적, 임시적)
단일 행 서브쿼리 : =, <, <=, >, >=, <> 연산자로 얻은 서브쿼리 결과 1개 이하 행을 반환
복수 행(중첩) 서브쿼리 : IN, ANY, ALL, EXISTS 등의 연산자로 얻은 서브쿼리 결과 여러개 행을 반환
JOIN
2개 이상의 테이블을 결합하여 쿼리를 실행하는 것
ON 을 이용해서 결합조건을 지정해주어야 함
INNER JOIN
ON 으로 지정한 결합 조건에 일치하는 행만을 2개의 테이블로부터 가져오는 것
SELECT 선택할 열 목록 FROM 테이블1 INNER JOIN 테이블2 ON 결합조건;
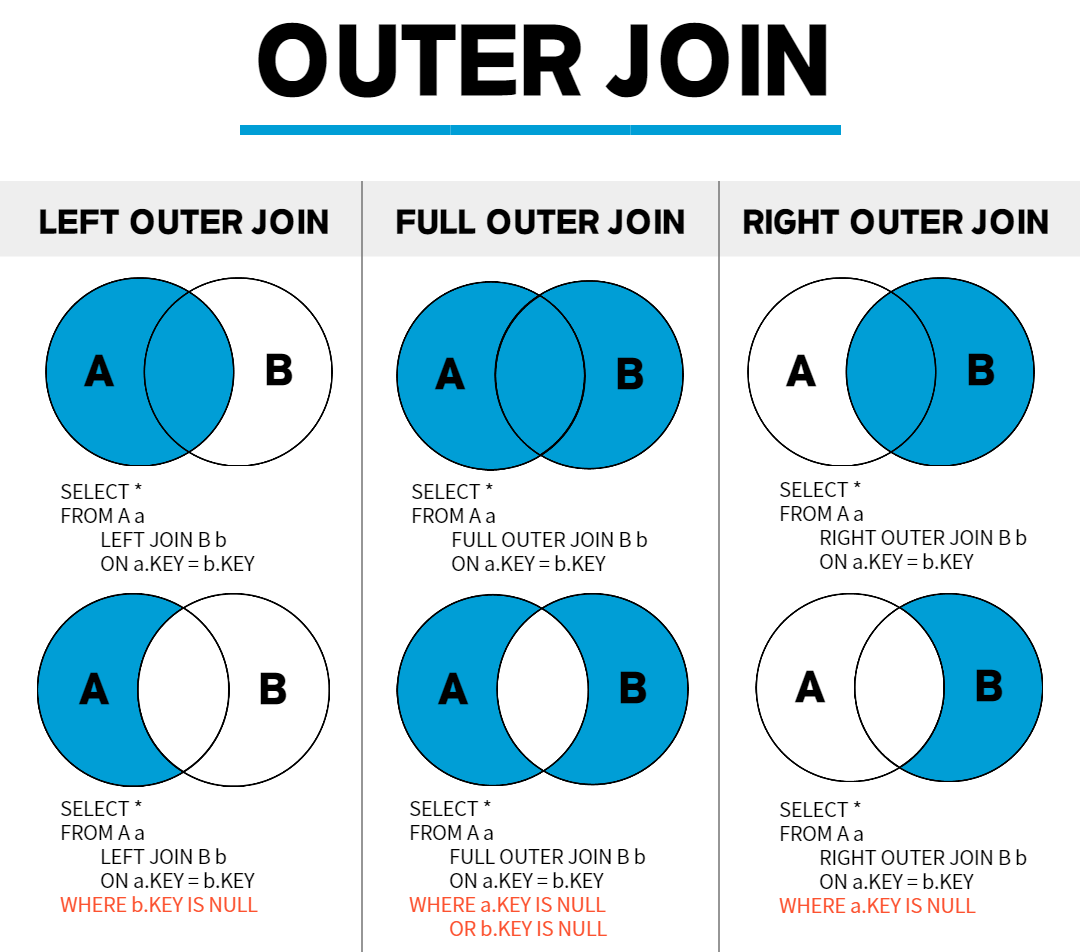
OUTER JOIN
한 쪽 테이블을 기준으로 전체 행을 표시하고 다른 테이블은 조건에 맞는 행이 있으면 표시하는 것
특별한 이유(쿼리 자동 생성으로 테이블1, 테이블2의 쿼리에서 순서를 변경할 수 없는 경우 등)가 아니면 LEFT OUTER JOIN 사용
SELECT 선택할 열 목록 FROM 테이블1 LEFT OUTER JOIN 테이블2 ON 결합조건;
SELECT 선택할 열 목록 FROM 테이블1 RIGHT OUTER JOIN 테이블2 ON 결합조건;
체크포인트 (SQL 코딩의 기술 참조)
데이터 필터링과 검색
LIKE 제대로 쓰기
LIKE '%keyword%'처럼 전후방 모두 와일드카드를 사용하면 인덱스를 사용할 수 없다.
LIKE는 최대한 자세하게
일치하거나 누락된 레코드를 찾아낼 때
이론적으로는 EXISTS가 NOT IN보다 빠름
또는 LEFT JOIN을 사용하고 WHERE에서 NULL값을 찾는 Frustrated JOIN 사용하기
GROUP BY
GROUP BY 절의 작동 원리를 이해하자
집계 함수를 하나도 사용하지 않을 때 GROUP BY 절은 SELECT DISTINCT와 동일하게 수행된다
집계 수행 전 WHERE 절이 적용된다
GROUP BY 절은 필터링된 데이터 집합을 집계한다
HAVING 절은 집계된 데이터를 다시 필터링한다
ORDER BY 절은 변형된 데이터 집합을 정렬한다
SELECT 절에서 집계 함수나 집계 계산에 포함되지 않은 컬럼은 GROUP BY 절에 명시해야 한다
GROUP BY 절은 간단하게 만들자
HAVING 절의 진정한 힘은 한 그룹의 집계 결과를 다른 집계 값과 비교하는 능력에 있다.
별칭으로 SELECT 절에서 계산을 수행하거나, HAVING 절에 사용할 수 없다. 해당 표현식을 그대로 재사용해야 한다. (?)
복잡한 문제를 해결하려면 GROUP BY나 HAVING 절을 사용하자
SELECT SUM(col) AS total
GROUP BY ...
HAVING SUM(col) ...;
GROUP BY 절 없이 최댓값, 최솟값을 찾자
서브쿼리
서브쿼리를 어디에 사용할 수 있는지 알아두자
일반적으로 테이블 이름을 쓸 수 있는 곳이라면 어디에나 서브 쿼리를 이용할 수 있다.
테이블 서브쿼리: FROM, JOIN 등에 사용
단일 컬럼 서브쿼리: IN, NOT IN 조건에 사용
스칼라 서브쿼리
연관성 있는 서브쿼리와 연관성 없는 서브쿼리의 차이점을 파악하자
서브쿼리 대신조인을 사용해 더효율적인쿼리를 작성하자
SELECT NAME
FROM BEERSTYLE
WHERE CountryFK IN (
SELECT CountryID
FROM Countries
WHERE CountryNm = "Belgium"
);
SELECT S.NAME
FROM STYLE AS S
INNER JOIN Countries AS c
ON S.CountryFK = C.CountryID
WHERE C.CountryNm = "Belgium";
조인
LEFT JOIN의 오른쪽 데이터를 올바르게 걸러내자
OUTER JOIN에서는 잘못된 결과를 내는 COUNT(*) 함수를 사용하지 말자
'*'를 사용해 COUNT를 하면 row 자체를 카운트한다. 즉 모든 컬럼의 값이 NULL로 채워져 있어도 카운트가 이루어진다. 반면에 컬럼명을 사용해 COUNT를 하면 해당 컬럼의 값이 NULL이면 카운트하지 않는다.
NULL 값이 있는 로우를 포함해 모든 로우의 개수를 세기 : COUNT(*)
컬럼 값이 NULL이 아닌 로우의 개수만 세기 : COUNT(컬럼명)
EXPLAIN, STRAIGHT JOIN(왼쪽 테이블부터 읽는 조인), SEMI JOIN(메인 쿼리 테이블과 서브쿼리 결과를 조인)